Рене Декарт (фр. René Descartes) — великий французский математик и философ XVII века.
Рене Декарт не является создателем декартова дерева, однако он является создателем декартовой системы координат, которую мы все знаем и любим.
Декартово дерево же определяется и строится так:
- Нанесём на плоскость набор из $n$ точек. Их $x$ зачем-то назовем ключом, а $y$ приоритетом.
- Выберем самую верхнюю точку (с наибольшим $y$, а если таких несколько — любую) и назовём её корнем.
- От всех вершин, лежащих слева (с меньшим $x$) от корня, рекурсивно запустим этот же процесс. Если слева была хоть одна вершина, то присоединим корень левой части в качестве левого сына текущего корня.
- Аналогично, запустимся от правой части и добавим корню правого сына.
Заметим, что если все $y$ и $x$ различны, то дерево строится однозначно.
Если нарисовать получившуюся структуру на плоскости, то получится действительно дерево — по традиции, корнем вверх:
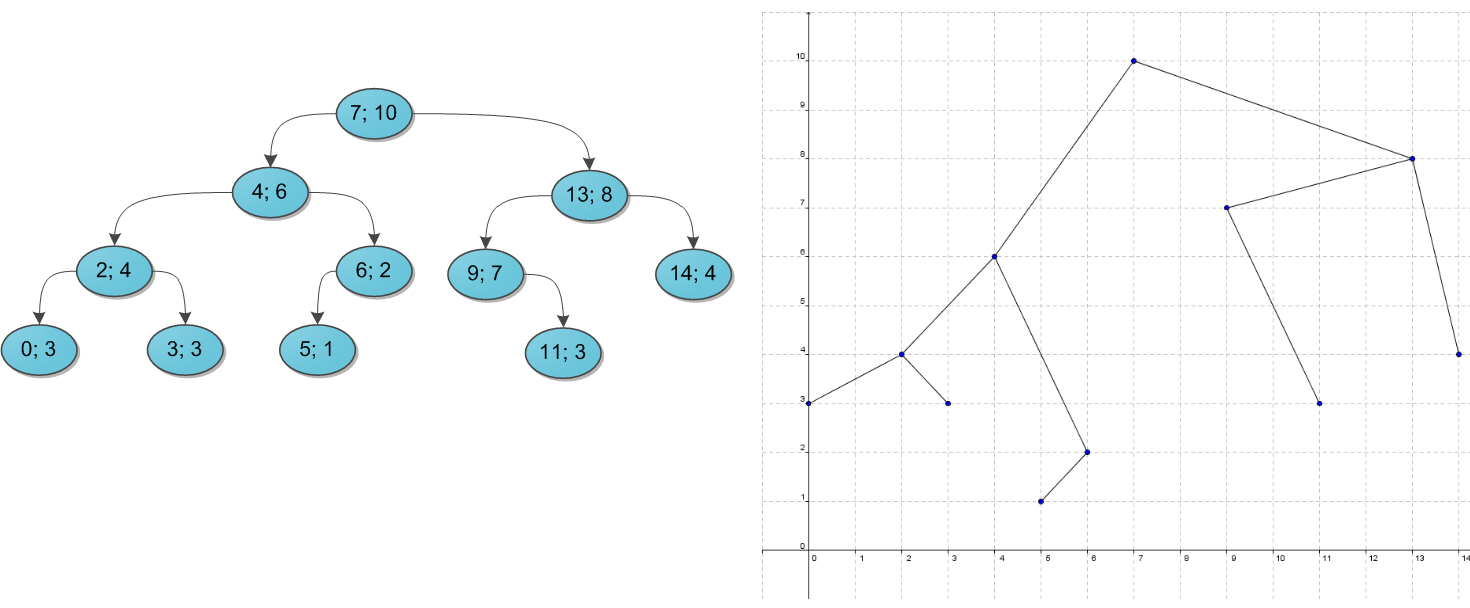
Таким образом, декартово дерево — это одновременно бинарное дерево по $x$ и куча по $y$. Поэтому ему придумали много альтернативных названий:
- Дерамида (дерево + пирамида)
- Дуча (дерево + куча)
- ПиВо (пирамида + дерево)
- КуРево (куча + дерево)
- Treap (tree + heap)
По-английски его обычно называют cartesian или treap, а по-русски часто сокращают до «ДД».
#Как бинарное дерево поиска
С небольшими модификациями, декартово дерево умеет всё то же, что и любое бинарное дерево поиска, например:
- добавить число $x$ в множество;
- определить, есть ли в множестве число $x$;
- найти первое число, не меньшее $x$ — аналогично
lower_bound; - найти количество чисел в промежутке $[l, r]$.
Как и во всех сбалансированных деревьях поиска, все операции работают за высоту дерева: $O(\log n)$.
#Приоритеты и асимптотика
В декартовом дереве логарифмическая высота дерева гарантируется не инвариантами и эвристиками, а теорией вероятностей: оказывается, что если все приоритеты ($y$) выбирать случайно, то средняя глубина вершины будет логарифмической. Поэтому ДД ещё называют рандомизированным деревом поиска.
Теорема. Ожидание глубины вершины в декартовом дереве равно $O(\log n)$.
Доказательство. Введем функцию $a(x, y)$ равную единице, если $x$ является предком $y$, и нулем в противном случае. Такие функции называются индикаторами.
Глубина вершины равна количеству её предков, и поэтому
$$ d_i = \sum_{j=1}^n a(j, i) $$ Её матожидание равно $$ E[d_i] = E[\sum_{j \neq i} a(j, i)] = \sum_{j \neq i} E[a(j, i)] = \sum_{j \neq i} E[a(j, i)] = \sum_{j \neq i} p(j, i) $$где $p(x, y)$ это вероятность, что $a(x, y) = 1$, то есть что вершина $x$ это предок вершины $y$. Здесь мы воспользовались важным свойством линейности: матожидание суммы чего угодно равна сумме матожиданий этого чего угодно.
Теперь осталось посчитать эти вероятности по всем возможным предкам и сложить. Но сначала нам понадобится вспомогательное утверждение.
Лемма. Вершина $x$ является предком $y$, если у неё приоритет больше, чем у всех вершин из полуинтервала $(x, y]$ (без ограничения общности, будем считать, что $x < y$).
Необходимость. Если $x$ не самая высокая, то где-то между $x$ и $y$ есть вершина с большим приоритетом, чем у $x$. Она не может быть потомком $x$, а значит $x$ и $y$ будут разделены ей.
Достаточность. Если справа от интервала будет какая-то вершина с большим приоритетом, то её левым сыном будет какая-то вершина, которая будет являться предком $x$. Таким образом, всё, что справа от $y$, ни на что влиять не будет.
У всех вершин на любом отрезке одинаковая вероятность иметь наибольший приоритет. Объединяя этот факт с результатом леммы, мы можем получить выражение для искомых вероятностей — чтобы вершина $x$ была предком $y$, её приоритет должен быть больше, чем у всех $|x - y|$ остальных на отрезке с $x$ по $y]$:
$$ p(x, y) = \frac{1}{|x-y|+1} $$ Теперь, чтобы найти матожидание глубины, эти вероятности надо просуммировать: $$ E[d_i] = \sum_{j \neq i} p(j, i) = \sum_{j \neq i} \frac{1}{|i-j|+1} = \sum_{j < i} \frac{1}{i - j} + \sum_{j > i} \frac{1}{j - i} \leq 2 \cdot \sum_{k=2}^n \frac{1}{k} = O(\log n) $$Перед последним переходом мы получили сумму гармонического ряда.
Примечательно, что ожидаемая глубина вершин зависит от их позиции: вершина из середины должна быть примерно в два раза глубже, чем крайняя.
Упражнение. Выведите по аналогии с этим рассуждением асимптотику quicksort.
#Реализация
Декартово дерево удобнее всего писать на указателях и структурах.
Создадим структуру Node, в которой будем хранить ключ, приоритет и указатели на левого и правого сына:
struct Node {
int key, prior;
Node *l = 0, *r = 0;
Node(int key) : key(key), prior(rand()) {}
};
Указателя на корень дерева достаточно для идентификации всего дерева. Поэтому, когда мы будем говорить «функция принимает два дерева» на самом деле будем иметь в виду указатели на их корни. К нулевому указателю же мы будем относиться, как к «пустому» дереву.
Объявим две вспомогательные функции, изменяющие структуру деревьев: одна будет разделять деревья, а другая объединять. Как мы увидим, через них можно легко выразить почти все функции, которые нам потом понадобятся.
#Merge
Принимает два дерева (два корня, $L$ и $R$), про которые известно, что в левом все вершины имеют меньший ключ, чем все в правом. Их нужно объединить в одно дерево так, чтобы ничего не сломалось: по ключам это всё ещё дерево, а по приоритетами — куча.
Сначала выберем, какая вершина будет корнем. Здесь всего два кандидата — левый корень $L$ или правый $R$ — просто возьмем тот, у кого приоритет больше.
Пусть, для однозначности, это был левый корень. Тогда левый сын корня итогового дерева должен быть левым сыном $L$. С правым сыном сложнее: возможно, его нужно смерджить с $R$. Поэтому рекурсивно сделаем merge(l->r, r) и запишем результат в качестве правого сына.
Node* merge(Node *l, Node *r) {
if (!l) return r;
if (!r) return l;
if (l->prior > r->prior) {
l->r = merge(l->r, r);
return l;
}
else {
r->l = merge(l, r->l);
return r;
}
}
#Split
Принимает дерево $P$ и ключ $x$, по которому его нужно разделить на два: $L$ должно иметь все ключи не больше $x$, а $R$ должно иметь все ключи больше $x$.
В этой функции мы сначала решим, в каком из деревьев должен быть корень, а потом рекурсивно разделим его правую или левую половину и присоединим, куда надо:
pair<Node*, Node*> split(Node *p, int x) {
if (!p) return {0, 0};
if (p->key <= x) {
auto [l, r] = split(p->r, x);
p->r = l;
return {p, r};
}
else {
auto [l, r] = split(p->l, x);
p->l = r;
return {l, p};
}
}
#Пример: вставка
merge и split сами по себе не очень полезные, но помогут написать всё остальное.
Например, чтобы добавить число $x$ в дерево, мы можем разрезать его по $x$ через split, создать новую вершину с одним числом $x$, и склеить через merge три получившихся дерева:
Node *root = 0;
void insert(int x) {
auto [l, r] = split(root, x);
Node *t = new Node(x);
root = merge(l, merge(t, r));
}
#Пример: модификация для суммы на отрезке
Иногда нам нужно написать какие-то модификации для более продвинутых операций.
Например, нам может быть интересно иногда считать сумму чисел на отрезке. Для этого в вершине нужно хранить также своё число и сумму на своем «отрезке»:
struct Node {
int val, sum;
// ...
};
При merge и split надо будет поддерживать эту сумму актуальной.
Вместо того, чтобы модифицировать и merge, и split под наши хотелки, напишем вспомогательную функцию upd, которую будем вызывать при обновлении детей вершины:
int sum(Node* v) { return v ? v->sum : 0; }
// обращаться по пустому указателю нельзя -- выдаст ошибку
void upd(Node* v) { v->sum = sum(v->l) + sum(v->r) + v->val; }
В merge и split теперь можно просто вызывать upd перед тем, как вернуть вершину, и тогда ничего не сломается:
Node* merge(Node *l, Node *r) {
// ...
if (...) {
l->r = merge(l->r, r);
upd(l);
return l;
}
else {
// ...
}
}
pair<Node*, Node*> split(Node *p, int x) {
// ...
if (...) {
// ...
upd(p);
return {p, r};
}
else {
// ...
}
}
Тогда при запросе суммы нужно просто вырезать нужный отрезок и запросить эту сумму:
int sum(int l, int r) {
auto [T, R] = split(root, r);
auto [L, M] = split(T, l);
int res = sum(M);
root = merge(L, merge(M, R));
return res;
}
#Небольшой рефакторинг
Реализация большинства операций всегда примерно одинаковая — вырезаем отрезок с $l$ по $r$, что-то с ним делаем и склеиваем обратно.
Дублирующийся код — это плохо. Давайте воспользуемся всей мощью C++ и определим функцию, которая принимает другую функцию, которая в свою очередь уже будет делать полезные вещи на нужном отрезке:
int apply(int l, int r, auto f) {
auto [T, R] = split(root, r);
auto [L, M] = split(T, l);
int res = f(M);
root = merge(L, merge(M, R));
return res;
}
Применять её нужно так:
apply(l, r, sum);
Для большинства операций удобно туда передать лямбду, если она ещё не была реализована для upd.