Алгоритм Дейкстры (англ. Dijkstra’s algorithm) находит кратчайшие пути от заданной вершины $s$ до всех остальных в графе без ребер отрицательного веса.
Существует два основных варианта алгоритма, время работы которых составляет $O(n^2)$ и $O(m \log n)$, где $n$ — число вершин, а $m$ — число ребер.
#Основная идея
Заведём массив $d$, в котором для каждой вершины $v$ будем хранить текущую длину $d_v$ кратчайшего пути из $s$ в $v$. Изначально $d_s = 0$, а для всех остальных вершин расстояние равно бесконечности (или любому числу, которое заведомо больше максимально возможного расстояния).
Во время работы алгоритма мы будем постепенно обновлять этот массив, находя более оптимальные пути к вершинам и уменьшая расстояние до них. Когда мы узнаем, что найденный путь до какой-то вершины $v$ оптимальный, мы будем помечать эту вершину, поставив единицу ($a_v=1$) в специальном массиве $a$, изначально заполненном нулями.
Сам алгоритм состоит из $n$ итераций, на каждой из которых выбирается вершина $v$ с наименьшей величиной $d_v$ среди ещё не помеченных:
$$ v = \argmin_{u | a_u=0} d_u $$(Заметим, что на первой итерации выбрана будет стартовая вершина $s$.)
Выбранная вершина отмечается в массиве $a$, после чего из из вершины $v$ производятся релаксации: просматриваем все исходящие рёбра $(v,u)$ и для каждой такой вершины $u$ пытаемся улучшить значение $d_u$, выполнив присвоение
$$ d_u = \min (d_u, d_v + w) $$где $w$ — длина ребра $(v, u)$.
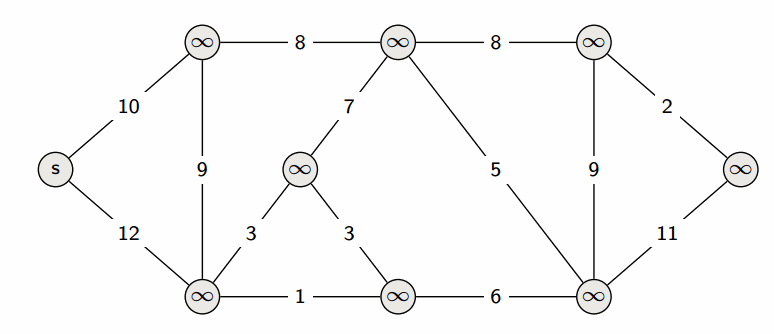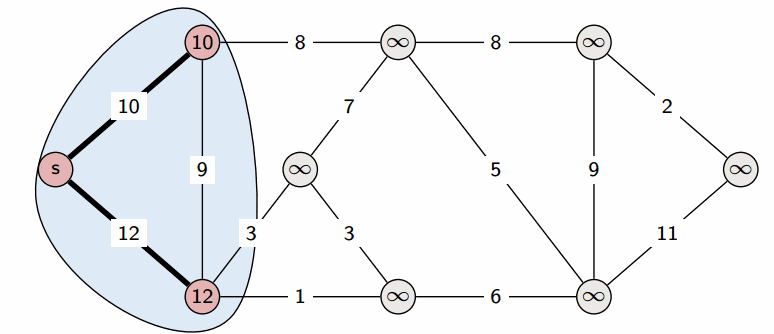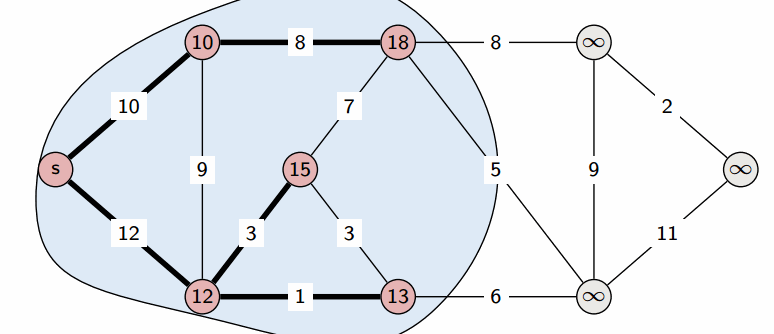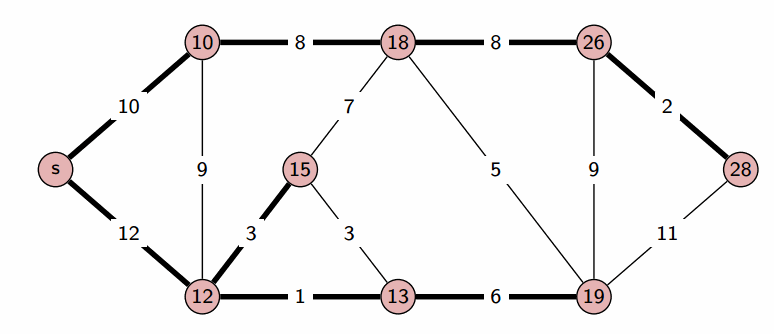
На этом текущая итерация заканчивается, и алгоритм переходит к следующей: снова выбирается вершина с наименьшей величиной $d$, из неё производятся релаксации, и так далее. После $n$ итераций, все вершины графа станут помеченными, и алгоритм завершает свою работу.
#Корректность
Обозначим за $l_v$ расстояние от вершины $s$ до $v$. Нам нужно показать, что в конце алгоритма $d_v = l_v$ для всех вершин (за исключением недостижимых вершин — для них все расстояния останутся бесконечными).
Для начала отметим, что для любой вершины $v$ всегда выполняется $d_v \ge l_v$: алгоритм не может найти путь короче, чем кратчайший из всех существующих (ввиду того, что мы не делали ничего кроме релаксаций).
Доказательство корректности самого алгоритма основывается на следующем утверждении.
Утверждение. После того, как какая-либо вершина $v$ становится помеченной, текущее расстояние до неё $d_v$ уже является кратчайшим, и, соответственно, больше меняться не будет.
Доказательство будем производить по индукции. Для первой итерации его справедливость очевидна — для вершины $s$ имеем $d_s=0$, что и является длиной кратчайшего пути до неё.
Пусть теперь это утверждение выполнено для всех предыдущих итераций — то есть всех уже помеченных вершин. Докажем, что оно не нарушается после выполнения текущей итерации, то есть что для выбранной вершины $v$ длина кратчайшего пути до неё $l_v$ действительно равна $d_v$.
Рассмотрим любой кратчайший путь до вершины $v$. Обозначим первую непомеченную вершину на этом пути за $y$, а предшествующую ей помеченную за $x$ (они будут существовать, потому что вершина $s$ помечена, а вершина $v$ — нет). Обозначим вес ребра $(x, y)$ за $w$.
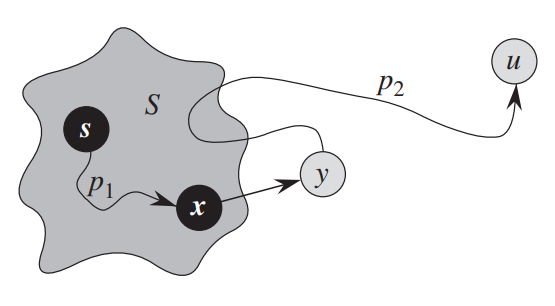
Так как $x$ помечена, то, по предположению индукции, $d_x = l_x$. Раз $(x,y)$ находится на кратчайшем пути, то $l_y=l_x+w$, что в точности равно $d_y=d_x+w$: мы в какой-то момент проводили релаксацию из уже помеченный вершины $x$.
Теперь, может ли быть такое, что $y \ne v$? Нет, потому что мы на каждой итерации выбираем вершину с наименьшим $d_v$, а любой вершины дальше $y$ на пути расстояние от $s$ будет больше. Соответственно, $v = y$, и $d_v = d_y = l_y = l_v$, что и требовалось доказать.
#Время работы и реализация
Единственное вариативное место в алгоритме, от которого зависит его сложность — как конкретно искать $v$ с минимальным $d_v$.
#Для плотных графов
Если $m \approx n^2$, то на каждой итерации можно просто пройтись по всему массиву и найти $\argmin d_v$.
const int maxn = 1e5, inf = 1e9;
vector< pair<int, int> > g[maxn];
int n;
vector<int> dijkstra(int s) {
vector<int> d(n, inf), a(n, 0);
d[s] = 0;
for (int i = 0; i < n; i++) {
// находим вершину с минимальным d[v] из ещё не помеченных
int v = -1;
for (int u = 0; u < n; u++)
if (!a[u] && (v == -1 || d[u] < d[v]))
v = u;
// помечаем её и проводим релаксации вдоль всех исходящих ребер
a[v] = true;
for (auto [u, w] : g[v])
d[u] = min(d[u], d[v] + w);
}
return d;
}
Асимптотика такого алгоритма составит $O(n^2)$: на каждой итерации мы находим аргминимум за $O(n)$ и проводим $O(n)$ релаксаций.
Заметим также, что мы можем делать не $n$ итераций а чуть меньше. Во-первых, последнюю итерацию можно никогда не делать (оттуда ничего уже не прорелаксируешь). Во-вторых, можно сразу завершаться, когда мы доходим до недостижимых вершин ($d_v = \infty$).
#Для разреженных графов
Если $m \approx n$, то минимум можно искать быстрее. Вместо линейного прохода заведем структуру, в которую можно добавлять элементы и искать минимум — например std::set так умеет.
Будем поддерживать в этой структуре пары $(d_v, v)$, при релаксации удаляя старый $(d_u, u)$ и добавляя новый $(d_v + w, u)$, а при нахождении оптимального $v$ просто беря минимум (первый элемент).
Поддерживать массив $a$ нам теперь не нужно: сама структура для нахождения минимума будет играть роль множества ещё не рассмотренных вершин.
vector<int> dijkstra(int s) {
vector<int> d(n, inf);
d[root] = 0;
set< pair<int, int> > q;
q.insert({0, s});
while (!q.empty()) {
int v = q.begin()->second;
q.erase(q.begin());
for (auto [u, w] : g[v]) {
if (d[u] > d[v] + w) {
q.erase({d[u], u});
d[u] = d[v] + w;
q.insert({d[u], u});
}
}
}
return d;
}
Для каждого ребра нужно сделать два запроса в двоичное дерево, хранящее $O(n)$ элементов, за $O(\log n)$ каждый, поэтому асимптотика такого алгоритма составит $O(m \log n)$. Заметим, что в случае полных графов это будет равно $O(n^2 \log n)$, так что про предыдущий алгоритм забывать не стоит.
#С кучей
Вместо двоичного дерева «правильнее» использовать более специализированную структуру, которая поддерживает именно добавление элементов и нахождение минимума: кучу. Удалять произвольные элементы в ней немного сложнее, поэтому вместо этого будем просто игнорировать все повторные вершины.
vector<int> dijkstra(int s) {
vector<int> d(n, inf);
d[root] = 0;
// объявим очередь с приоритетами для *минимума* (по умолчанию ищется максимум)
using pair<int, int> Pair;
priority_queue<Pair, vector<Pair>, greater<Pair>> q;
q.push({0, s});
while (!q.empty()) {
auto [cur_d, v] = q.top();
q.pop();
if (cur_d > d[v])
continue;
for (auto [u, w] : g[v]) {
if (d[u] > d[v] + w) {
d[u] = d[v] + w;
q.push({d[u], u});
}
}
}
}
На практике вариант с priority_queue немного быстрее.
Помимо обычной двоичной кучи, можно использовать и другие. С теоретической точки зрения, особенно интересна Фибоначчиева куча: у неё все почти все операции кроме работают за $O(1)$, но удаление элементов — за $O(\log n)$. Это позволяет облегчить релаксирование до $O(1)$ за счет увеличения времени извлечения минимума до $O(\log n)$, что приводит к асимптотике $O(n \log n + m)$ вместо $O(m \log n)$.
#Восстановление путей
Часто нужно знать не только длины кратчайших путей, но и получить сами пути.
Для этого можно создать массив $p$, в котором в ячейке $p_v$ будет хранится родитель вершины $v$ — вершина, из которой произошла последняя релаксация по ребру $(p_v, v)$.
Обновлять его можно параллельно с массивом $d$. Например, в последней реализации:
if (d[u] > d[v] + w) {
d[u] = d[v] + w;
p[u] = v; // <-- кратчайший путь в u идет через ребро (v, u)
q.push({d[u], u});
}
Для восстановления пути нужно просто пройтись по предкам вершины $v$:
void print_path(int v) {
while (v != s) {
cout << v << endl;
v = p[v];
}
cout << s << endl;
}
Обратим внимание, что код распечатает путь в обратном порядке.