Для большого класса задач требуется решить следующую вспомогательную задачу.
Задача. Дано корневое дерево. Требуется отвечать на запросы нахождения наименьшего общего предка вершин $u_i$ и $v_i$, то есть вершины $w$, которая лежит на пути от корня до $u_i$, на пути от корня до $v_i$, и при этом самую глубокую (нижнюю) из всех таких.
По-английский эта задача называется least common ancestor — наименьший общий предок.
Для лучшего понимания — медленно (за линейное время) наименьшего общего предка можно искать так:
bool ancestor(int u, int v) {
return tin[u] <= tin[v] && tin[v] < tout[u];
}
int lca(int u, int v) {
while (!ancestor(u, v))
u = p[u];
return u;
}
Есть много самых разных способов её решать, и далее в этой главе мы рассмотрим основные. Конкретно в этой статье мы сведем её к задаче нахождения минимума на отрезке (и наоборот).
#Сведение к Static RMQ
Пройдёмся по дереву dfs-ом и выпишем два массива: глубины вершин и номера вершин. Записывать мы их будем как при входе в вершину, так и при выходе.
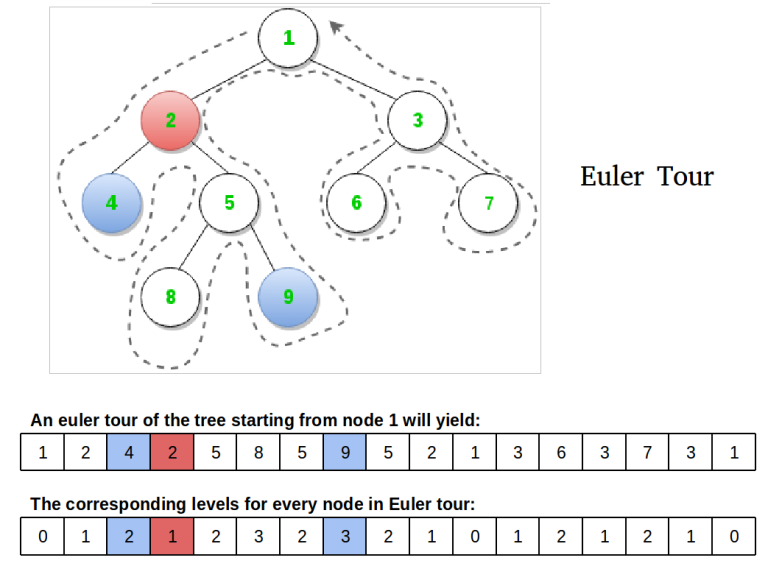
Пусть теперь поступил запрос: найти LCA вершин $v$ и $u$. Для определенности предположим, что $v$ в обходе встретилась раньше: $tin_v < tin_u$. Посмотрим на часть выписанного пути между моментом, когда мы вышли из $v$ и моментом, когда мы первый раз вошли в $u$. Так как любой простой путь между двумя вершинами в дереве единственный, где-то на этом отрезке мы должны были прийти в наименьший общий предок. При этом мы на этом пути точно не поднимались выше LCA, а значит LCA — это самая высокая вершина на этом пути.
Получается, что чтобы найти LCA, можно найти позицию минимума на отрезке $[tout_v, tin_u]$ в массиве глубин (первый выписанный массив) и посмотреть, какой вершине она соответствует в эйлеровом обходе (второй выписанный массив). Таким образом, задачу LCA можно свести к задаче RMQ (нахождению минимума на отрезке), что можно сделать, например, деревом отрезков за $O(\log n)$ на запрос.
Асимптотику времени запроса можно улучшить, используя тот факт, что мы на самом деле решаем задачу static RMQ, то есть у нас нет изменений массива. Для этого есть более подходящая структура — разреженная таблица, которая позволяет отвечать на запрос минимума за $O(1)$, но использует $O(n \log n)$ операций и памяти на препроцессинг с малой константой.
Оказывается, можно свести и обратно.
#Алгоритм Фарака-Колтона и Бендера
Disclaimer: алгоритм нахождения LCA, описываемый в этой секции, абсолютно бесполезен на практике, однако очень интересен с теоретической точки зрения.
Оказывается, что и LCA, и static RMQ можно считать за $O(1)$ времени на запрос и $O(n)$ времени на предподсчет.
На самом деле, в сведении LCA к RMQ, мы решаем не совсем полноценную задачу RMQ. Мы работаем не со всеми массивами целых чисел от 1 до $n$, а только с некоторыми — с теми, в которых любые два элемента отличаются ровно на единицу, потому что каждый переход это либо спуск, либо подъём в dfs. Это ограничение позволяет находить минимум на подотрезках подобных массивов быстрее.
#Предподсчет
Сделаем следующее: раз каждый элемента либо на единицу больше, либо на единицу меньше предыдущего, то сопоставим исходному массиву глубин булевый массив размера $(n - 1)$: на $i$-той позиции будет стоять единица, если следующее значение больше, и ноль если меньше. Этот массив нужно будет хранить в бинарном виде, чтобы можно было за константу получать булеву маску небольших подотрезков.
Первая часть предподсчёта. Возьмем константу $k = \lfloor \frac{\log n}{2} \rfloor$, и разделим исходный массив на блоки по $k$ элементов. На каждом блоке посчитаем минимум, а над этими минимумами построим sparse table.
Всего блоков таких блоков $O(\frac{2 n}{\log n})$, и поэтому построение работает за линейное время:
$$ O(\frac{2 n}{\log n} \log \frac{2 n}{\log n}) = O(\frac{2 n}{\log n} (\log 2n - \log \log n)) = O(n) $$ Вторая часть предподсчёта. Посчитаем для каждой возможной маски подъёмов / спусков размера $k$ максимальный спуск на ней — то есть пройдёмся по ней, поддерживая разницу встретившихся нулей и единиц, и запомним минимальное значение этого баланса. Это можно сделать за длину маски, помноженное на их количество: $$ O(k \cdot 2^k) = O(\frac{\log n}{2} 2^{\frac{\log n}{2}}) = O(\sqrt n \log n) $$Возможных масок получается немного — ради этого мы и делили логарифм на два при определении $k$
#Ответ на запрос
Теперь нам нужно с помощью посчитанных структур найти RMQ на каком-то отрезке $[l, r]$. Он включает в себя какие-то последовательные блоки и сколько-то оставшихся ячеек слева и справа, не вошедших ни в какой целый блок.
Для блочной части мы можем просто сделать запрос в sparse table — он будет работать за константу.
Для обеих не-блочных частей посчитаем ещё по кандидату на ответ. Для этого нужно прибавить к граничному элементу предподсчитанное значение минимума на маске оставшихся неблочных элементов — её можно за константу получить битовыми операциями над булевым массивом.
Просто посчитать все суффиксные и префиксные минимумы для всех блоков, чтобы обрабатывать второй случай, к сожалению, нельзя — есть один частный случай, когда запрос маленький и не накрывает никакой блок целиком. В данном случае нужно просто взять граничный элемент и прибавить к нему минимум от нужной маски из массива подъёмов.
#Static RMQ → LCA
Этот алгоритм очень важен с теоретической точки зрения, потому что позволяет решать не только LCA, но и в общем случае static RMQ за линейный предподсчет и константу на запрос.
Построим декартово дерево, в котором в качестве ключей $x_i$ возьмём индексы элементов, а в качестве приоритетов $y_i$ возьмём сами значения. Декартово дерево могло получиться несбалансированным (так как нет рандомизации приоритетов), но это нам и не нужно. Дальше просто применим описанный выше алгоритм к этому дереву, и теперь для нахождения минимума в исходном массиве можно просто запросить общего предка $l$-той и $r$-той вершины в дереве — его приоритет в декартовом дереве и будет искомым минимумом.
Чуть более подробно и с реализацией (автор это никогда не кодил и вам не советует) можно почитать у Емакса. Впрочем, на практике этот алгоритм использовать нецелесообразно из-за большой константы: слишком много чего нужно считать, чтобы избавиться от логарифма в асимптотике.